MuleSoft platform helps developers to work within an environment where any application architecture is well defined, so they can be focused on providing a solution to customer business needs, speeding up delivery time.
This is often true, but as Robert Martin says: “before you commit to a framework, make sure you could write it”. This could be radical but let’s put it in another way: you have not to reinvent the wheel every time, just make sure that you understand how it works so you can fix it if things go south. This is important, because if you believe in magic, you could get lost easily.
So, let’s start from the basics: deep inside, what is a Mule Runtime?
Meeting Mule Runtime
Mule Runtime is complex of course, but what’s based on? It’s basically a Java process, i.e. a JVM, that schedule tasks based on thread pools, sized according to available system resources. Simplifying, every application flows, during execution, are just tasks that borrow threads from available ones: when threads are over, several things can happen, so it’s important to understand how thread pools work and how are used by Mule Runtime.
In the next chapters we’ll see how Java Thread Pools work, to better understand how they are used in Mule 4. Finally, we’ll see how (and why) MuleSoft changed its threading profiling in version 4.3 (wait, such a change in a minor version? I know what you are thinking…).
Java Thread Pools
Let’s start with some definitions: what is a thread? According to Wikipedia,
In computer science, a thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler, which is typically a part of the operating system
so, to run some lines of code you need a thread: when you create a thread in Java, it’s actually mapped to Operating System level thread, whose capacity depends on hardware capabilities (i.e. CPU cores). To increase application performances, you need more threads, but it’s clear that you cannot create threads indefinitely because you can run out system resources. Of course CPUs can handle more threads than the number of their actual cores, simulating parallelism by performing context switching: workload is separated in unit of time that is dedicated only to one thread so, the more thread you have, the more time system will spend to switch context, trying to serve them all. Keep in mind also that even spawn new threads has a cost, so you need to calibrate how many threads your system can create and manage. This problem is usually addressed with Thread Pool Pattern.
With a Thread Pool, you can prepare a set of threads ready to be used several times, avoiding spawn cost. You can set some policies to determinate if it can grow when needed till a controlled limit: you can control how many threads your application can consume, avoiding system congestion. In Java, thread pools are implemented like this (thanks to this illuminating post):
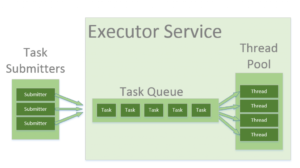
Each code execution is considered a task (in Mule 4 we’ll see that corresponds to a processor, thanks to Proactor Pattern): Java Executor Service is responsible for managing submitted task in a queue: once a thread of the target pool is free to be used, it will take care of completing next task in the queue. In normal situation, submitted task will not wait in queue and will be served as soon as possible by any ready thread of the pool: but what happen in a stressful situation? It depends on how thread pool has been configured.
When you create a thread pool, you can define 4 parameters:
- core size: it’s the initial pool size, that is the minimum size
- maximum size: it’s the maximum size a pool can grow
- queue size: it’s the queue size of task waiting to be served by a thread. It’s also used as a buffer that triggers pool growth if queue is full.
- keep alive time: it’s the time a thread will remain in the pool if pool has grown. Pool can shrink back to core size, not below.
So let’s imagine some scenarios: these are important because will explain us later why Mule 4.3 changed threading pool philosophy.
Scenario 1: core size equals to max size, no queue
In this situation, initial size is the maximum size a pool can have: each submitted task is immediately taken by a free thread. What happen if there’s no available threads? The task is rejected and the submitter receive an error. In term of macroscopic effects, for example, if you make an HTTP request to a situation like this, you’ll get an Internal Server Error response (500) or Service Unavailable (503) if using back-pressures mechanisms.
Scenario 2: core size less that max size, queue size greater than zero
This is the typical configuration where pool has an initial size and a finite queue. When there is no available thread in the pool, submitted task will wait its turn. Two things can happen here:
- a thread become available, so next task in the queue can be served;
- a new task come in queue, overcoming queue size: now the executor service is allowed to increase thread pool size with a new thread (to maximum its defined max size) in order to serve tasks in queue. This lead to other two scenarios:
- submitted tasks are served and newly created threads will be destroyed after “keep alive time” of inactivity;
- max pool size is still not enough: submitted task exceeding max size + queue size are rejected as of scenario 1.
This is the most used configuration because guarantee flexibility since reduce the cost of spawning new threads but can grow in a controlled manner to serve a burst of submitted tasks, going back to initial situation if not needed anymore.
Scenario 3: core size less that max size, no queue
This is a sub-case of scenario 2: pool has an initial size and a max size (greater than initial) but no queue. In case of saturation of initial pool size, pool will grow immediately because there’s no queue to buffer new thread spawn cost. Once max size is reached, new further submitted tasks are rejected.
Scenario 4: core size greater than zero, infinite queue size
This configuration is usually set for creating an event loop in a non-blocking environment, keeping number of core size closest to CPU cores number (in order to minimize context switch). Every task exceeding core size will wait its turn (there will be no rejection), so each thread must be freed very quickly, i.e. it’s suitable only for non-blocking operations, otherwise whole system will look like stuck.
Another scenario (even blocking) could be single batch process execution. By setting core size to one, you ensure that another batch execution will not be served until previous one is completed.
Mule 4 Execution Engine
Now we master Java thread pools, we can understand better choices MuleSoft engineers made in version 4.1/4.2 and then in 4.3.
First thing to point out is that version 4 marries Reactive Programming, using thread pools in non-blocking way, instead of classic multithreading model. What does it mean?
In Mule 3, each thread was responsible for executing a flow: you could control the thread pool associated with any flow execution. That means that you had full control and responsibility of tuning thread pool size associated with your flows. Nobody usually do that because it’s now easy: you need to estimate traffic and perform stress tests on your application in target environment to better understand how to properly set pools numbers and their sizes.
In Mule 4, the philosophy is totally different: any event processor in a flow is a task with metadata: based on these metadata, the runtime will decide to which thread pool submit the task. Source event flow will publish an incoming event to the first processor to start the flow execution and it will subscribe to latest processor to gather flow results, according to a Publish/Subscribe pattern. In result, each flow can be executed in several different threads, borrowed by different thread pools: Mule will try to minimize context switching.
So, which thread pools I can count on? It depends on Runtime version you are working on.
Mule 4.1 and 4.2 Runtime
In version 4.1 and 4.2, Execution Engine is based on 3 thread pools, shared at runtime level across all deployed applications (do not underestimate this point):
- CPU-Light: default one. It is meant to be used for non blocking operations (http requests) or very fast processors (< 10ms), like a logger;
- Blocking I/O: used for I/O blocking operations, like transactions, file, FTP or database access;
- CPU-Intensive: used by DataWeave processor or other slow processors (> 10ms).
In this version of Mule, a flow is not executed only by a thread: each processor are suitable for one of these pools, so the Runtime will decide where to schedule next processor, according to Proactor Pattern, like shown in this picture:
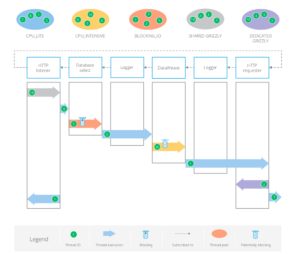
This is a representation of a flow, where each processor may be scheduled in a different thread pool (defined by different colors), according to the type of processor. All details and explanations can be found in this must-read post: “Thread management and auto-tuning in Mule 4“.
Why should I care about these stuffs? Because their sizing impact directly your application performance: you should know how they are automatically tuned based on your available system resources (memory and CPU cores). Here how they are calculated:
- CPU-Light:
- pool size: # of cores x 2
- queue size: 0
- Blocking I/O:
- core size: # of cores
- max size: max(2, # of cores + ((memory in kb – 245760) / 5120))
- queue size: 0
- keep alive time: 30 seconds
- CPU-Intensive:
- pool size: # of cores x 2
- queue size: # of cores x 2
You can check file conf/scheduler-pools.conf in your on-premise base runtime installation folder to discover these calculations. Of course, you can change and do some fine tuning if you think they are not enough. Giving these default numbers, do you see any analogy with some of the scenarios shown in previous chapter? Are they starting to ring some bells? Remember that these values are set at runtime level, so every application deployed in your runtime will share these pools!!
CPU-Light is comparable to Scenario 1: since it’s the default thread pool, there’s no queue and pool size is actually core and max size at the same time, it’s likely that you’ll get some task rejections in systems with single core, like the two smallest worker size on CloudHub, a kind of t2.micro EC2 AWS instance.
CPU-Intensive may suffers same problem than previous thread pool, but at least has a queue size to try to buffer bursted requests.
Blocking I/O is comparable to Scenario 3. It’s the classic thread pool that can grow or shrink, even if has no buffer queue. Its size is far way bigger that the others because most of the time its threads will wait for blocking operation to be completed. This kind of thread pool usually do not cause any problem since max size is pretty hight (depending on memory available and cores, could be more than 100 threads).
Likely for us, we can tune these settings, even if MuleSoft suggests to keep default values. As I said before, according to documentation, you can change default values at runtime level (usually on-premise) or at application level, suitable for CloudHub applications: in latter case, a new set of the three pools will be created, keeping default pools intact. This technique can come in handy even in on-premise installations, if a particular application has more demands.
Try to do a stress test on your application deployed on a 0.1 vCore on CloudHub, then multiply by 10 CPU Light and CLU Intensive pool size and perform the same test again: you won’t go back! You’d better to try several values before committing to a final decision, but such an increment is a good starting point. Keep in mint that the more threads you have, the more context switch you suffer, so you have to repeat stress test several times in order to find the right balance for your case.
Now that we know all the pitfalls we can encounter with runtime 4.2, let’s see what’s new in 4.3.
Mule 4.3 Runtime
Version 4.3 is mostly focused on performance so… guess what? MuleSoft engineers replaced the 3 pools with a singe thread pool, called UBER Pool that, surprise surprise, is tuned exactly like the former Blocking I/O thread pool!!
- Uber:
- core size: # of cores
- max size: max(2, # of cores + ((memory in kb – 245760) / 5120))
- queue size: 0
- keep alive time: 30 seconds
Now we have a unique thread pool shared among all applications at runtime level: they still continue to use Proactor Pattern, but the target pool is always the same. The difference is made by the processor that uses the thread: it may release it quickly to the pool if it’s a non-blocking operation or retain it if it’s blocking.
So, if you’re planning to upgrade to 4.3 and made a pool tuning to previous version, first give a try to this “new” threading profile, you won’t regret! If you wish, you can use the “dedicated” thread pool strategy, i.e. legacy strategy, to use the old 3 pools in version 4.3 and migrate smoothly.
Author: Andrea Como
